







































AI画像生成ツールはここ数年で急成長しています。ソーシャルメディアを見たり、プライムタイムのニュース番組を観たり、雑誌を読んだりすれば、AI画像生成に気づかないことはほとんどありません。(この記事を書いている時点で、スタジオジブリ風の画像が最新のバイラルブームになっています。)このようなAI画像生成は至る所にあり、時にはそれがAIによって作られたものだと気づかないことさえあります。もしこの楽しさに参加したい、あるいはビジネスのワークフローにAIを活用したいのであれば、このリストにあるアプリケーションがご希望のものを提供してくれるでしょう。
筆者は2015年のGoogle Deep Dream以来、AI画像生成ツールについて書いてきました。それは、コンピュータサイエンスの研究室外でこれらのツールについて現実的に考えられてきた期間とほぼ同じです。そして、その進化の速さに非常に興奮しています。
今回は、芸術的な価値や、様々なツールがアーティストを置き換えるのか、補完するのか、または訓練データにおける著作権侵害などの難しい議論には触れないようにします。代わりに、AI画像生成ツールが、さまざまなテキストや画像のプロンプトから素晴らしい結果を生み出せるようになったという事実に焦点を当てたいと思います。
テキストから画像を生成するAIアプリを使って、数時間遊んでみる価値は十分にあります。たとえ結果が気に入らなくても、技術的な観点から評価するだけでも十分に興味深い体験となるでしょう。良し悪しは別として、私たちは今、そうした成果物を日々目にしており、今後さらに増えていくことは間違いありません。
一、AI画像生成ツールの仕組み
AI画像生成ツールは、テキストのプロンプトを受け取り、それにできるだけ忠実に対応する画像を生成します。これにより、非常にユニークで多彩な表現の可能性が広がります。たとえば、「カナダ人の男性がカエデの森をムースに乗って歩いている印象派風の油絵」や、「伝統的なパブでビールを楽しむ、ふわふわした大型のアイルランド・ウルフハウンドを描いたフェルメール風の絵画」、さらには「月面にいるロバの写真」のようなプロンプトまで、発想次第でどんなものでもリクエスト可能です。
実質的な制限は、ユーザーの想像力と、AI画像生成ツールがそのプロンプトをどれだけ正確に解釈できるか、そして著作権や不適切なコンテンツ(暴力表現など)を防ぐために設けられたフィルタリング機能にかかっています。たとえば、先ほどのフェルメール風のプロンプトは以前なら問題なく生成できましたが、現在では特定のアーティスト名を使用しているため、一部の厳格なツールではブロックされることもあります。
ほとんどのAI画像生成ツールは、かなり似たような仕組みで動作します。数百万または数十億の画像とテキストのペアを使用してニューラルネットワーク(基本的に、人間の脳を大まかに模倣した非常に高度なコンピュータアルゴリズム)を訓練し、物の認識方法を学習させます。無数の画像を処理することで、犬や赤色、ヴェルメール、そしてその他すべてのものが何であるかを学習します。この訓練が終わると、AIはほぼどんなプロンプトでも解釈できるようになり、モデル画像やaiモデル画像、さらにはai写真合成によるリアルなビジュアル表現を生成できるようになります。ただし、正確に実行できるように設定するには技術が必要です。
次のステップは、実際にAI画像生成をレンダリングすることです。最新のAI画像生成ツールは、通常「拡散」と呼ばれるプロセスを使用しますが、OpenAIの最新の画像生成では、少し異なるプロセス「自己回帰」を使用しています。本質的に、AI画像生成ツールはランダムなノイズのフィールドから始め、それを一連のステップで編集してプロンプトの解釈に合った画像に仕上げます。これは、曇った空を見上げて、犬のように見える雲を見つけ、その後、指を鳴らしてそれをどんどん犬らしくしていくようなものです。
ここで深く掘り下げる前に、あまり誇張しすぎないようにしておきたいと思います。テキストから画像を生成するツールは非常に印象的な機能を持っており、その背後には膨大なデータで訓練された高度な画像認識モデルが存在します。ただし、それによって今後一切、製品撮影が不要になるわけではありません。
もし少しユニークなビジュアルが必要な場合には、こうしたツールは大いに役立ちます。一方で、非常に具体的で現実的なビジュアルが求められる場合は、専門のカメラマンに依頼したり、必要な画像をライセンス購入する方が確実でしょう。同様に、ブログ記事のヘッダー画像などを作成する目的で使用する場合も、ストックフォトサイトで目的に合った画像を探す方が、結果的に時間を節約できる可能性があります。
二、優れたAI画像生成ツールの条件
ここ数年でAI画像生成ツールが爆発的に人気を集めているのには理由があります。というのも、それ以前の技術は正直なところ、あまり実用的ではなかったからです。技術的には非常に高度で、研究者にとっては面白いものでしたが、実際に生成される画像は期待外れのものが多く、2021年に登場した初代DALL·Eでさえ「面白いおもちゃ」といった印象にとどまっていました。
しかし現在では、テキストから画像を生成するAI画像生成モデル同士に競争が生まれるほど精度が上がり、テキストだけでなく文字自体の描写もある程度できるようになっています。もし「今、一番優れているモデル」だけを知りたいなら、Artificial Analysisが提供する「Image Arena」をチェックするのが良いでしょう。ただし、現時点ではトップクラスのモデルが十数種類も存在しており、性能差はそこまで大きくありません。そのため、使いやすさや機能面といった要素が、より重要な比較ポイントになっています。
今回、最適なAI画像生成ツールを選ぶにあたって、いくつかの厳しい選定基準を設けました。対象としたのは、テキストプロンプト(および一部では画像プロンプト)から直接画像を生成できるツール。複数の写真をアップロードしてAIがポートレートを生成するタイプのアプリは、Stable Diffusionなどをベースにしていて楽しいものですが、汎用的な画像生成ツールとは異なるため、今回は対象外としています。
また、AI画像生成モデルを活用するだけのツールではなく、モデルそのものにも注目しました。たとえば、NightCafeはコミュニティやアプリとしては優れていますが、FLUXやStable Diffusion、DALL·E 3、Google ImagenといったオープンソースモデルやAPIの実行環境に過ぎないため、単独での紹介はしていません。
そのほか、操作の簡便さ、細かいカスタマイズ機能(画像の高解像化など)、価格体系、そして何よりも生成結果のクオリティを重視しました。現在のトップモデルでは、以前のような「奇妙で非現実的な画像」が出力されることはかなり減っています。
三、AI画像生成ツール比較一覧
| 最適な用途 | 対応ツール | 料金 | 提供 | |
| GPT-4o | 画像プロンプトへの高い対応力 | ChatGPT Plus または Enterprise、API経由で利用可能 | 無料プランでは1日2枚まで画像生成が可能/有料プランは公式サイトをご覧ください。 | OpenAI |
| Stable Diffusion | カスタマイズ性とコントロール性 | NightCafe、Tensor.Art、Civitaiなど多数のアプリで利用可能/API経由/ローカルサーバーへのダウンロードも可能 | 価格はプラットフォームによって異なる | Stability AI |
| Adobe Firefly | AI画像生成を写真で使用する | firefly.adobe.com、Photoshop、Express、その他のAdobe製品 | 無料クレジットに制限あり/有料プランは公式サイトをご覧ください。 | Adobe |
1.画像プロンプトへの忠実性に最適なAI画像生成ツール
GPT-4o(ChatGPT)

GPT-4oのメリット
- 使い方が非常に簡単で、画像プロンプトの再現性が抜群
- ChatGPT Plusに含まれているため、コストパフォーマンスが高いAI画像生成ツール
GPT-4oのデメリット
- 動作がかなり遅い
- コントロール(細かい指示)の反映にムラがある
- 月額20ドルは、画像生成だけでなくChatGPT全体を利用したくない場合は割高に感じる
OpenAIがDALL·Eモデルでテキストから画像を生成する波を起こした後、しばらくは言語モデルの影に隠れていました。DALL·E 2やDALL·E 3も登場当初は優秀でしたが、他モデルにすぐ追い抜かれてしまいました。しかし今回、OpenAIは本気を見せています。ChatGPTを支えるマルチモーダルモデルであるGPT-4oが、ネイティブに画像生成機能を搭載したのです。
GPT-4oは現時点で最高クラスのAI画像生成のひとつです。Artificial Analysisのランキングでもトップに君臨しています。操作はとにかく簡単で、「こんな画像がほしい」とChatGPTに伝えるだけで生成してくれます。ただし、GPT-4oは拡散(ディフュージョン)ではなく自己回帰(オートリグレッシブ)モデルを用いているため、他のAI画像生成ツールに比べて非常に時間がかかり、一度に1枚しか生成できません。たまに数枚作る程度なら問題ありませんが、多用する場合は注意が必要です。
それでもGPT-4oの真骨頂は、画像プロンプトへの忠実性にあります。プロンプト通りのスタイル再現力は群を抜いており、例えば自分の写真をアップロードして「ピカソ風に」「ヴェルメール風に」「ジブリ風に」と指示すれば、まさにそのテイストで仕上げてくれます。また、生成後のフィードバック反映も得意で、「ここだけ変えて」と伝えると大抵思い通りに調整してくれます。DALL·E 3(GPTとしても利用可能)と比べても、大幅に進化したことが実感できるでしょう。
- 価格:ChatGPT Plusに含まれています。AI画像生成だけを単独で利用するプランはありません。有料プランは公式サイトをご覧ください。
2.カスタマイズ性と制御性に最適なAI画像生成ツール
Stable Diffusion

Stable Diffusionのメリット
- 多くのAIアート生成プラットフォームで利用可能
- 手頃な価格でカスタマイズ性が高く、驚異的なパワーを発揮し、総じて高品質な結果が得られる
Stable Diffusionのデメリット
- 開発元の会社(Stability.ai)が経営危機に陥るなど不安定な状況
- 利用方法がひとつにまとまっておらず、手軽に始めづらい
stable diffusion使い方については、MidjourneyやIdeogramとは異なり、Stable Diffusionがオープンライセンスです。これにより、技術的な知識があれば誰でもモデルをダウンロードして自分のPC上で実行でき、特定用途向けに再学習(ファインチューニング)することも可能です。過去数年間、AIで芸術的なポートレートや建築パース、歴史画などを生成するサービスのほとんどが、この仕組みを採用してきました。
しかし、オープンな体制は同時に混乱を招きがちです。実際、Stable Diffusionを開発した研究者たちが設立したStability.ai社は2024年に経営危機に陥り、最新モデルやライセンス条件が大いに批判を浴び、研究チームの大半が新会社を立ち上げて去っていきました。
現在、Stability.ai社はかろうじて危機を乗り越えたように見えますが、この一連の出来事はStable Diffusionを不安定な立場に置いています。既存AI画像生成モデルは依然としてトップクラスの性能を誇り、特定用途向けに最適化されたファインチューニング版も数多く存在し、非常に人気があります。しかし、この状況がどれだけ続くかは不透明です。最新バージョンのStable Diffusion 3.5は優れたモデルですが、従来版ほどの普及や利用しやすさはまだ伴っていません。
最も人気のあるStable Diffusion版を安定的に使うなら、NightCafe、Tensor.Art、CivitaiなどのAI画像生成ツール経由がおすすめです。ほとんどのプラットフォームで無料クレジットが配布されているので、まずはお試しで使ってみるとよいでしょう。ただし、一部のサービスでは大手SNSのようなコンテンツモデレーションが不十分な場合があるため、不適切な画像が表示されるリスクもあります。
もしそれらを避けたい、または完全に制御したい場合は、Stable Diffusionをダウンロードしてローカル環境で動かすのが最も確実です。
- 価格:プラットフォームによるが、stable diffusion無料クレジットを提供。試してから有料プランに移行可能です。有料プランは公式サイトをご覧ください。
3.生成画像を写真に統合するのに最適なAI画像生成ツール
Adobe Firefly
Adobe Fireflyのメリット
- PhotoshopをはじめとするAdobeアプリとの連携が抜群
- 既存画像とのマッチング処理に優れている
Adobe Fireflyのデメリット
- 純粋なテキストから画像を生成するモデルとしてはやや不安定
Adobeは15年以上にわたって自社のアプリにAI機能を組み込んできた実績があり、他ツールとの統合性に関しては最もパワフルなテキスト画像生成ツールのひとつを提供しています。AdobeのAI画像生成モデル「Firefly」は、Web上やAdobe Express経由で無料で試すことができますが、最も本領を発揮するのは最新版のPhotoshop内です。
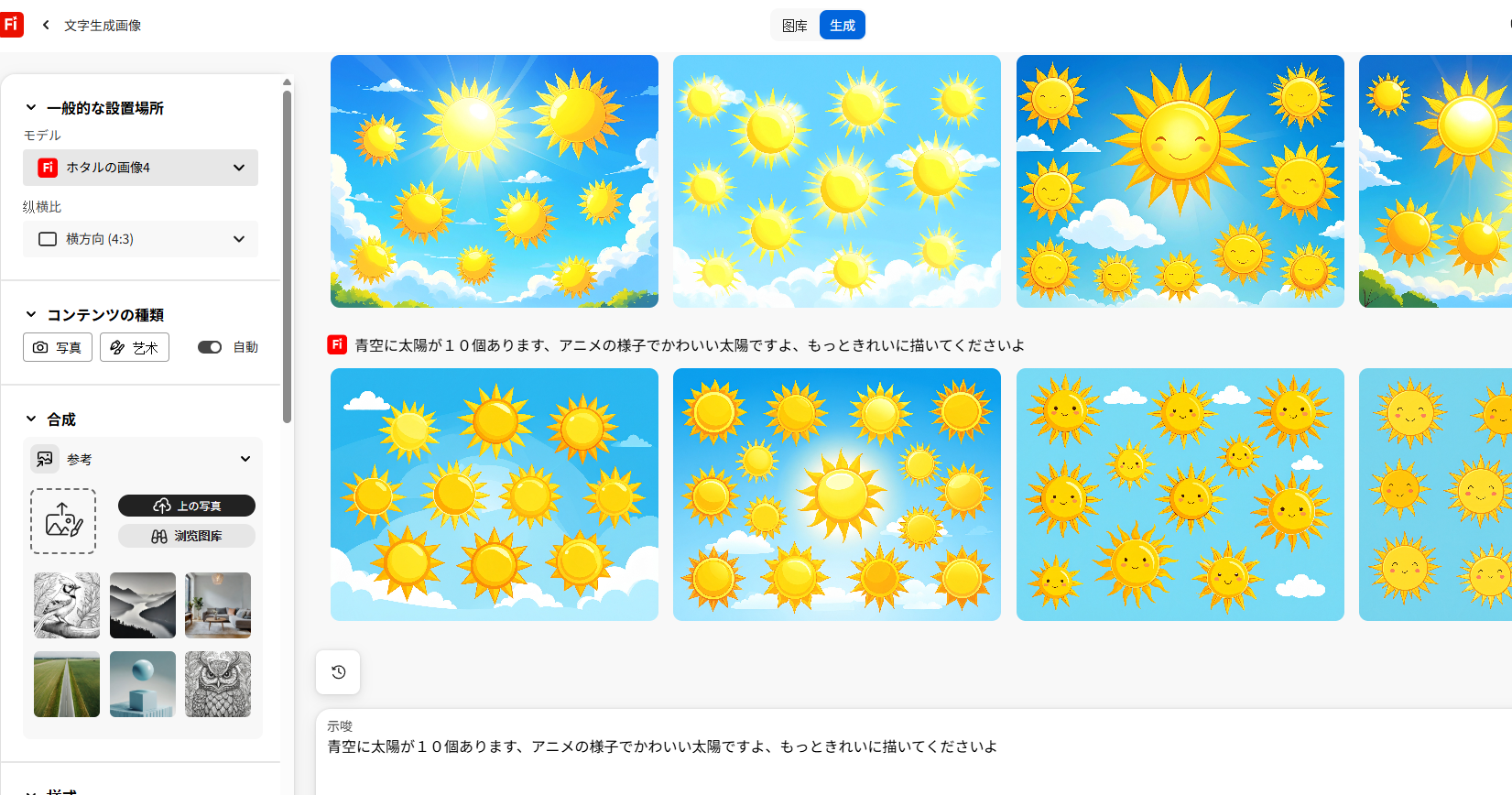
Fireflyはさまざまな機能を持っています。詳細なテキスト記述から新しい画像を生成できるのに加え、高精細なアートモデル画像の生成にも対応しています。入力した文字に対して「トーストでできた文字のような表現」のように視覚効果を付けたり、ベクターアートの色を変更したり、既存の画像にAI生成の要素を追加したりできます。これらはすべてWebアプリでも試せますが、特に最後の機能がFireflyの真骨頂です。
テキストからの画像生成という観点で見ると、Fireflyの結果はやや当たり外れがあります。MidjourneyのようなトップAI画像生成モデルと同等の画像を生み出すこともあれば、逆に「これは何を意図していたのか?」と疑問に思うこともあります。一方で、業界標準の画像編集ソフトであるPhotoshopとの統合はまさに次元が違います。
特に注目すべき2つの機能が「生成塗りつぶし(Generative Fill)」と「生成拡張(Generative Expand)」です。「生成塗りつぶし」では、Photoshopの通常の選択ツールで画像の一部を選び、ボタンをクリックしてプロンプトを入力するだけで、その部分を別の要素に置き換えることができます。「生成拡張」では、画像の外側に新たな領域を追加できます。これらのツールは画像の文脈を理解したうえで処理を行っており、例えば、森の画像を追加した場合にPhotoshopが自動的に元の画像と同じ被写界深度のぼかしを適用するなど、非常に自然な仕上がりになります。
DALL·EやStable DiffusionなどのAI画像生成ツールが画像生成AIの話題を広めたのに対して、Adobe Fireflyはプロフェッショナルの現場で本格的に活用される未来を示唆する、初めての実用的ツールと言えるでしょう。もはや「ちょっとした遊び」ではなく、毎日Adobe製品を使っている数百万人のユーザーがすぐに利用できるプロ仕様のツールです。
Fireflyの料金:無料クレジットあり。Firefly Standardの有料プランは公式サイトをご覧ください。
四、AI画像生成ツールの使い方ガイド
生成した画像をプレゼンテーションやミーティングで活用するなら、NearHubのスマートホワイトボードがオススメです。 ・Windows 11搭載の大型タッチディスプレイで、AIが作成した高解像度イメージをそのまま表示・編集可能です。 ・チームとリアルタイムでブレインストーミングしながらビジュアルを共有できます。 ▶ NearHubスマートボードを見る(日本語サイト)
五、AI画像生成の法的・倫理的課題
AI画像生成は今や至るところで見かけるようになりましたが、それが「どう使うべきか」「どう使うべきでないか」について疑問を抱くべきでないというわけではありません。
現時点では、AI画像生成に関する明確な法律は整備されていません。そしてこの問題は、著作権と著作権侵害という両側面に関係しています。米国著作権局は、「AIによって生成されたコンテンツは、プロセスに人間の重要な関与がない限り、著作権の保護対象にはならない」と示唆しています。同時に、AIの学習に使用されたアーティストの作品を保護するための規則も存在していません(そのため、Adobe Fireflyはライセンス取得済みの画像およびパブリックドメインのコンテンツのみを学習に使用しています)。
この状況はすでに訴訟にもつながっています。たとえば、Stability AIは、Getty Imagesや複数のアーティストたちから、モデル画像を無断で使用されたとして訴えられています。また、いくつかのAI画像生成ツールに対しては、集団訴訟も起こされています。
SNS投稿やブログのアイキャッチ画像など、ちょっとした用途でAI画像生成を使う分には問題になる可能性は低いかもしれませんが、明確なルールが存在しない以上、AI画像を軸に戦略を立てることにはリスクが伴います(ちなみに、ハリウッドではすでに静かに導入が進んでいるようです)。
もうひとつの大きな問題が「バイアス」です。現在のAIには人間と同様のバイアスが多く含まれており、それがステレオタイプの再生産や有害なコンテンツの生成につながることがあります。実際、私自身もいくつかのアプリをテストしている際にそうした出力に直面しました。一方で、一部のツールは、AI画像生成に多様性を取り入れるよう意図的に工夫しています。AIによるバイアスを防ぐためには、私たち人間自身が生成されたコンテンツを確認し、プロンプトを工夫して不要な偏りをできる限り取り除く必要があります。
六、AI画像生成ツールの今後の展望
AI画像生成の分野は急速に進化しており、この記事を更新するたびにより強力なモデルが登場しています。GPT-4o、Stable Diffusion、Adobe Fireflyといったテキストから画像を生成するモデルは、難解なコンセプトを繰り返し描き出す能力が驚くほど向上しており、生成されるモデル画像やaiモデル画像の品質も飛躍的に高まっています。現時点ではまだニッチなツールではあるものの、このペースで進化し続ければ、業界全体に大きな変革をもたらす可能性があります。
